
Decision trees are a type of machine-learning algorithm that can be used for both classification and regression tasks. They work by learning simple decision rules inferred from the data features. These rules can then be used to predict the value of the target variable for new data samples.
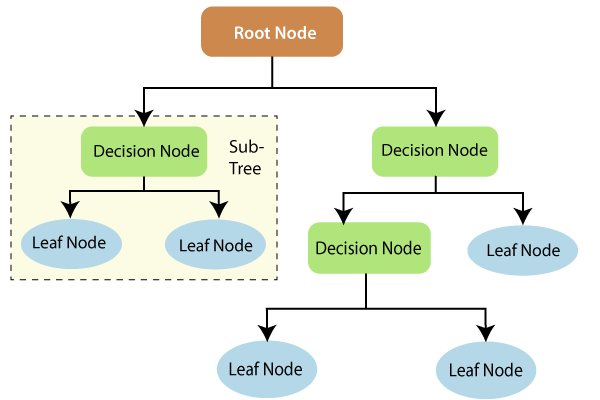
Components of a Decision Tree
Before we dive into the types of Decision Tree Algorithms, we need to know about the following important terms:
Root Node: It is the topmost node in the tree, which represents the complete dataset. It is the starting point of the decision-making process.
Internal Node: A node that symbolizes a choice regarding an input feature. Branching off of internal nodes connects them to leaf nodes or other internal nodes.
Leaf/Terminal Node: A node without any child nodes that indicates a class label or a numerical value.
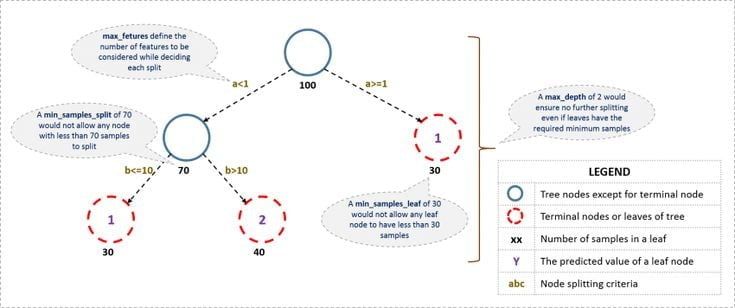
Working of the Decision Tree Algorithm
The algorithm works by recursively splitting the data into smaller and smaller subsets based on the feature values. At each node, the algorithm chooses the feature that best splits the data into groups with different target values.
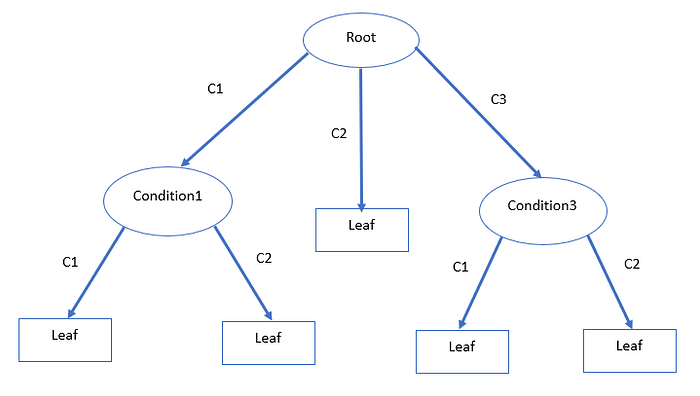
Types of Decision Tree Algorithms
There are several types of decision tree algorithms, such as ID3 (Iterative Dichotomiser 3), C4.5, CART (Classification and Regression Trees), CHAID (Chi-Square Automatic Interaction Detection), and MARS (Multivariate Adaptive Regression Splines).
Conclusion
In conclusion, decision trees are an essential machine learning tool that is appreciated for their versatility, interpretability, and ease of use. They are prone to overfitting, though, which results in unduly complicated trees. Pruning methods are employed to lessen this. Moreover, decision trees provide the foundation for ensemble techniques that aggregate many trees to increase prediction accuracy, such as Random Forests and Gradient Boosting.